Photo Calendar Recommendation System
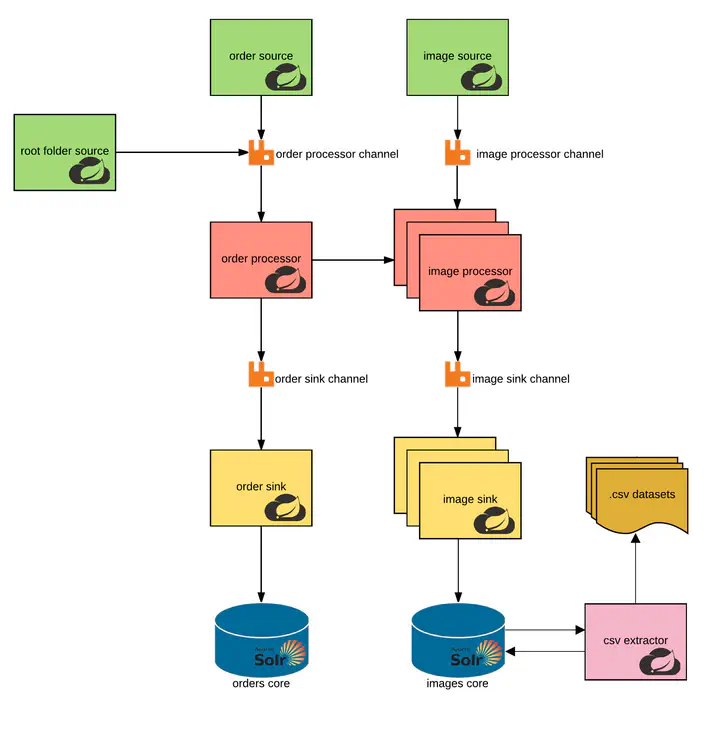 Data Extraction Pipeline Architecture
Data Extraction Pipeline Architecture
Project Overview (March 2016 – December 2016)
At Know Center Research, I developed a machine learning system for a digital photo printing company. The system intelligently assigned user-uploaded images to appropriate calendar months, significantly enhancing the user experience by automating photo selection.
Quick Highlights:
- End-to-end ML pipeline analyzing image metadata
- Technologies: Java, Spring Boot, RabbitMQ, Apache Solr, PySpark, Weka
- Achieved substantial accuracy improvements over manual/random assignments
- Scalable solution suitable for production workloads
Technical Challenges
Key challenges addressed included:
- Designing a scalable microservices architecture for image processing
- Extracting and analyzing relevant image metadata efficiently
- Developing accurate predictive models for assigning images to calendar months
- Establishing a robust, scalable data pipeline
Technologies & Methods
The solution leveraged various technologies and approaches:
- Architecture: Microservices using Java 8, Spring Boot, Swagger, and RabbitMQ
- Data Storage: Apache Solr for efficient metadata indexing and retrieval
- Machine Learning: Weka (J48, Random Forest, Naive Bayes classifiers)
- Data Processing: PySpark, HDFS, Hadoop, and Python for large-scale analysis and visualization
- CI/CD: Jenkins, Maven, Git, JUnit, and integration testing for quality assurance
- Development: IntelliJ IDEA, Agile methodology with Scrum
Results & Impact
- Significantly improved accuracy in month assignment compared to manual/random assignments
- Robust handling of images with incomplete metadata
- Enhanced user experience through streamlined calendar creation
- Delivered a scalable, reliable system capable of production deployment
Personal Contribution
As the primary developer on this project, I:
- Designed and implemented the data extraction pipeline
- Conducted feature engineering and classifier evaluations using Weka
- Performed large-scale data analysis using PySpark and Hadoop
- Developed scalable microservices architecture adhering to industry best practices
- Created comprehensive test suites (JUnit, integration tests)
- Authored detailed project documentation
Tomislav Đuričić
Researcher / Machine Learning Engineer / Software Engineer
My research interests include social-based recommender systems, graph neural networks and user modeling.