PyChemFlow: an automated pre-processing pipeline in Python for reproducible machine learning on chemical data
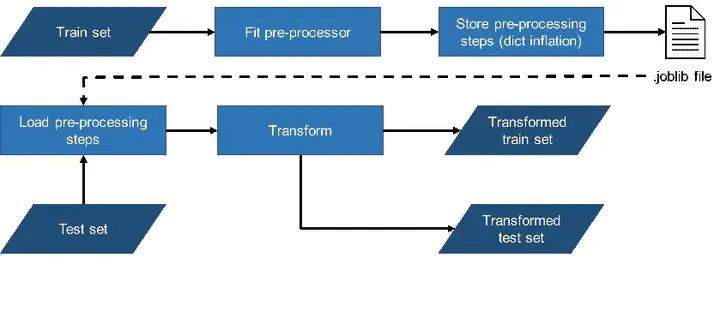 A schematics representation of the transformer object.
A schematics representation of the transformer object.
Abstract
PyChemFlow is a Python library for automated and reproducible data pre-processing. Based on open-source code, PyChemFlow has simple requirements that rely on pandas, scikit-learn and joblib. The library’s backbone is built up of transformer objects, which are fully constructed during the PyChemFlow fitting process using training data and can be conveniently stored using joblib. The user can run the library with a one-line command after splitting data into train and validation sets or while working with additional data. This is especially useful when reproducibility is critical. PyChemFlow also offers the ability to persistently store metadata, in addition to providing customizable and configurable data manipulation steps.
Tomislav Đuričić
Researcher / Machine Learning Engineer / Software Engineer
My research interests include social-based recommender systems, graph neural networks and user modeling.