Home
Publications
Projects
Talks
Contact
Light
Dark
Automatic
Machine Learning
Beyond-Accuracy: A Review on Diversity, Serendipity, and Fairness in Recommender Systems Based on Graph Neural Networks
Recommender systems are vital to online platforms, with Graph Neural Network (GNN) approaches showing excellent accuracy. However, beyond-accuracy metrics like diversity, serendipity, and fairness significantly impact user satisfaction. This review examines these dimensions in GNN-based recommenders, analyzing recent developments that balance accuracy with these broader objectives. We explore how various model development stages—from data preprocessing to training methodologies—affect these metrics. The paper addresses practical challenges in maintaining high accuracy while enhancing diversity, serendipity, and fairness, and outlines future research directions for more holistic GNN-based recommender systems. Our contribution lies in providing a comprehensive understanding of the multidimensional considerations essential to effective recommender system design.
Tomislav Đuričić
,
Dominik Kowald
,
Emanuel Lacić
,
Elisabeth Lex
PDF
Cite
Project
DOI
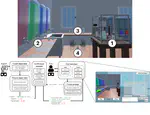
DDIA - Data Driven Immersive Analytics
Research project enhancing digital twin interactions and immersive analytics using personalized AI, AR/VR interfaces, and physiological sensing for improved remote collaboration, support, and training in industry.
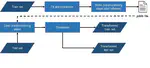
PyChemFlow: an automated pre-processing pipeline in Python for reproducible machine learning on chemical data
PyChemFlow is a Python library for automated, reproducible data pre-processing that leverages transformer objects built on minimal dependencies. It enables one-line execution with train-validation splits, persistent storage of transformers and metadata, and customizable data manipulation steps, making it ideal for applications requiring strict reproducibility.
Mario Lovrić
,
Tomislav Đuričić
,
Hussain Hussain
,
Bono Lucić
,
Roman Kern
PDF
Cite
DOI
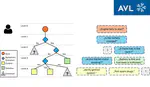
AVL Research Project: Intelligent Fault Tree Construction for Automotive Diagnostics
Research collaboration between Graz University of Technology and AVL List GmbH focused on applying sequential recommendation methods and text embeddings to automate and enhance automotive diagnostic fault tree construction.
My friends also prefer diverse music: homophily and link prediction with user preferences for mainstream, novelty, and diversity in music
This study examines homophily on Last.fm based on users’ preferences for mainstream, novel, or diverse music content. We compare friendship connections to listening profiles and evaluate these features for link prediction. Results show that friends share similar artist preferences, with diversity being a stronger predictor of friendship than mainstream or novelty preferences. While high-novelty users show strong homophily, they have lower artist profile similarity. Mainstream/novel/diverse features perform comparably to artist profiles in link prediction, with combined features yielding best results—though adding no value when graph-based features are available. These insights inform music recommendation, user modeling, and cold-start link prediction.
Tomislav Đuričić
,
Dominik Kowald
,
Markus Schedl
,
Elisabeth Lex
PDF
Cite
Project
DOI
The interplay between communities and homophily in semi-supervised classification using graph neural networks
This study investigates how community structure and homophily influence Graph Neural Networks (GNNs) in semi-supervised node classification tasks. By systematically modifying eight datasets and measuring GNN performance with and without these structural properties, we demonstrate their significant impact on classification accuracy and reveal insights about their interaction. We introduce an information-theoretic metric to quantify community-label correlation, providing practical guidelines for model selection based on graph structure. Our findings enhance understanding of GNN capabilities and improve model selection for semi-supervised node classification tasks.
Hussain Hussain
,
Tomislav Đuričić
,
Elisabeth Lex
,
Denis Helić
,
Roman Kern
PDF
Cite
Project
DOI
Should We Embed in Chemistry? A Comparison of Unsupervised Transfer Learning with PCA, UMAP, and VAE on Molecular Fingerprints
This study examines three unsupervised dimensionality reduction techniques (PCA, UMAP, and VAEs) for toxicology classification tasks. The research compares these embedding methods against standard molecular fingerprint models and explores transfer learning by training embedders on external chemical compound datasets. By testing various embedding dimensions and external dataset sizes, the findings demonstrate that UMAP can effectively complement established techniques like PCA and VAE for pre-compression in toxicology. However, VAE’s generative approach shows superior performance in pre-compression for classification accuracy.
Mario Lovrić
,
Tomislav Đuričić
,
Han T.N. Tran
,
Hussain Hussain
,
Emanuel Lacić
,
Morten A. Rasmussen
,
Roman Kern
PDF
Cite
Project
DOI
On the Impact of Communities on Semi-supervised Classification Using Graph Neural Networks
This study examines how community structures in graphs affect Graph Neural Networks (GNNs) in node classification tasks. Through experiments on six datasets, researchers found that community structures significantly impact GNN performance. When nodes in a community mostly share the same label, disrupting the community structure dramatically reduces performance. Conversely, when labels don’t correlate with communities, graph structure becomes less relevant and simple feature-based models perform comparably. The research provides insights and guidelines for selecting appropriate models based on graph structure characteristics.
Hussain Hussain
,
Tomislav Đuričić
,
Elisabeth Lex
,
Roman Kern
,
Denis Helić
PDF
Cite
Project
DOI
Empirical Comparison of Graph Embeddings for Trust-Based Collaborative Filtering
In this work, we study the utility of graph embeddings to generate latent user representations for trust-based collaborative filtering. In a cold-start setting, on three publicly available datasets, we evaluate approaches from four method families - (i) factorization-based, (ii) random walk-based, (iii) deep learning-based, and (iv) the Large-scale Information Network Embedding (LINE) approach. We find that across the four families, random-walk-based approaches consistently achieve the best accuracy. Besides, they result in highly novel and diverse recommendations. Furthermore, our results show that the use of graph embeddings in trust-based collaborative filtering significantly improves user coverage.
Tomislav Đuričić
,
Hussain Hussain
,
Emanuel Lacić
,
Dominik Kowald
,
Denis Helić
,
Elisabeth Lex
PDF
Cite
Project
DOI
COGSTEPS - Crossing the Gap: Startup Education and Support for Researchers
ERASMUS+ project designed to bridge academia and the startup ecosystem, developing a platform and educational programs to foster innovation and entrepreneurial skills among researchers and scientists.
»
Cite
×